

I’ve watched dozens of computer vision startups burn through millions of dollars chasing ideas that were doomed from day one. Not because the founders were incompetent. Not because the technology wasn’t ready. But because they skipped the unglamorous, critical validation work that separates viable CV products from expensive science projects.
After building computer vision systems across transportation security, retail, healthcare, and port automation, I can tell you: the gap between “this demo works” and “this is a business” is where most CV startups die.
Here are the five failure modes I see repeatedly—and more importantly, how to fix them before you write a single line of code.
Failure Mode #1: You’re Solving for the Demo, Not the Deployment
The trap: Your model gets 94% accuracy on your test set. Investors are impressed. You raise a seed round. Then you deploy to production, and performance collapses to 60%.
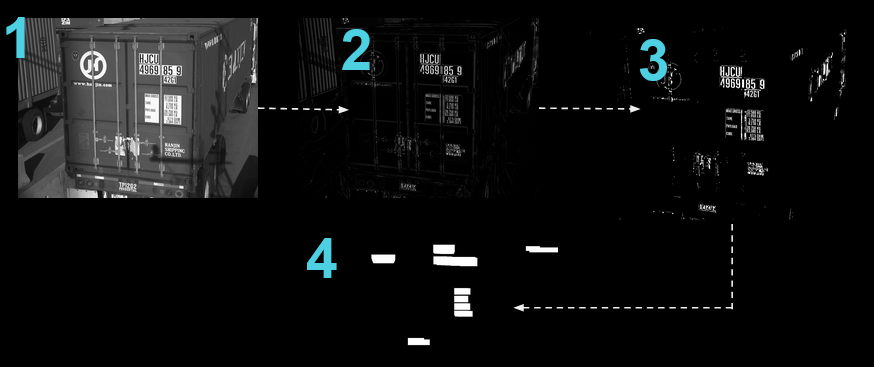
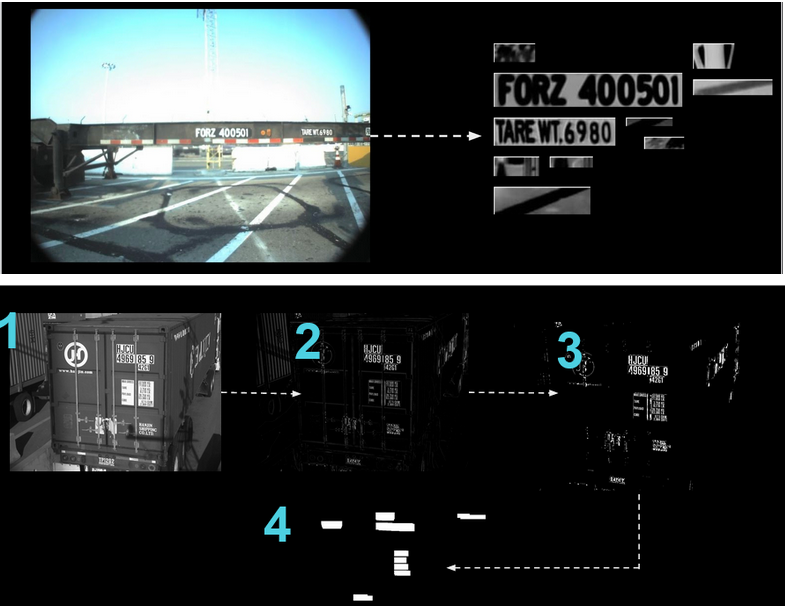
I’ve seen this in every industry. The LPR system performed well on high-resolution test images but failed in real-world conditions, such as rain, darkness, or when the camera was repositioned. The retail analytics solution that nailed detection in one store’s lighting but broke in 40% of other locations. The imaging model was trained on pristine academic datasets that couldn’t handle real-world image quality.
Why it happens: You’re optimizing for the wrong metric. Demo accuracy is measured under controlled conditions with curated data. Production performance is measured under Murphy’s Law conditions: bad lighting, weird angles, occlusion, motion blur, seasonal changes, hardware variations, and adversarial users.
The fix before you build:
– Do a data audit FIRST. Before touching any models, collect real samples from your actual deployment environment. Not synthetic data. Not academic datasets. Real, messy, representative data from the exact context where your system will run.
– Define your minimum viable performance based on worst-case conditions, not average ones. In license plate recognition (LPR) projects, I’ve learned to account for real-world scenarios where plates aren’t the standard European style — those with large, clean numbers and minimal visual noise. Instead, I’ve had to handle plates with complex backgrounds, varying formats, and visual artifacts that make recognition far more challenging.
– Calculate your annotation budget realistically. Quality-labeled data is expensive and time-consuming. If your business model requires you to label 100,000 images with pixel-perfect segmentation masks, you need to know that cost upfront.
Red flag question: Can you describe the three most challenging scenarios your system will encounter in production? If not, you’re not ready to build.
Failure Mode #2: You Ignored the Edge Cases That Will Kill You
**The trap:** Your product works for 95% of inputs. But that remaining 5%? Those edge cases will destroy your business, your reputation, or worse—cause actual harm.
In biometric systems, edge cases can mean discrimination. In manufacturing, they mean production line shutdowns. In healthcare, they mean patient safety issues. In port automation, they mean million-dollar cargo delays.
**Why it happens:** Edge cases are boring. They’re hard to collect. They don’t make good demos. So founders deprioritize them. But in production, edge cases aren’t 5% of your problem—they’re 80% of your engineering time, 90% of your support costs, and 100% of your liability exposure.
**The fix before you build:**
– **Run a pre-mortem.** Gather people who understand your deployment context and ask: “Our system just caused a major incident. What happened?” The answers reveal your edge cases.
– **Study adjacent failures.** Look at what went wrong with similar CV systems in other contexts. When Amazon shut down their CV recruiting tool, when facial recognition systems showed racial bias, when autonomous vehicles missed edge case scenarios—these are your warnings.
– **Budget for edge case handling from day one.** In every project I’ve led, edge case handling consumed 40-60% of development time. It’s not a “nice to have” you add later. It’s core architecture.
**Red flag question:** What happens when your system encounters an input type it’s never seen before? If your answer is “it probably won’t,” you’re in trouble.
## Failure Mode #3: Your Data Collection Strategy Is Naively Optimistic
**The trap:** Your business model requires continuous data collection from customers. You assume they’ll happily provide it. They won’t.
This killed a retail analytics startup I advised. Their model required stores to upload hundreds of hours of footage monthly. Stores agreed in principle. In practice? Less than 20% ever uploaded consistently. The data pipeline—the entire business model—collapsed.
**Why it happens:** You’re thinking about data from an ML perspective (“we need data to improve the model”), not from your customer’s perspective (“why would I spend time on this?”).
I’ve seen this across industries. Healthcare providers who won’t share patient images due to privacy concerns. Manufacturers who consider production line data proprietary. Port operators who can’t provide footage for security reasons.
**The fix before you build:**
– **Validate data access before product development.** Don’t assume. Get written commitments. Better yet, actually collect a pilot dataset from real potential customers before you build anything.
– **Design for data scarcity, not data abundance.** Can your system work with limited training data? Can you use synthetic data, transfer learning, or few-shot approaches? In scientific computing projects, we often had to work with hundreds of samples, not thousands.
– **Build data collection friction into your business model.** If customers need to actively upload data, you need incentive structures, not just product features. Make data contribution valuable to them, not just to you.
**Red flag question:** Have you actually attempted to collect real data from your target customers yet? If not, do that this week.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}